
前回は関数の定義と条件分岐を見てきました。
今回は条件分岐の補足と繰り返し処理(ループ)を学びます。
次回は繰り返し処理2(while文)を説明します。
今回も、無理のない範囲で新しい用語を導入していきます!
条件分岐の補足
まずは前回説明した条件分岐の補足から見ていきましょう。
実は if 文が行っていることは、その条件が成り立つかどうかの判定です。
つまり、条件が True になるかどうかを見ているということです。
その鍵を握るのが比較演算子です。確認してみましょう。
# 比較演算子を使うと、
# その条件(式)が成り立つかどうかを
# 真偽値(True or False)で教えてくれます
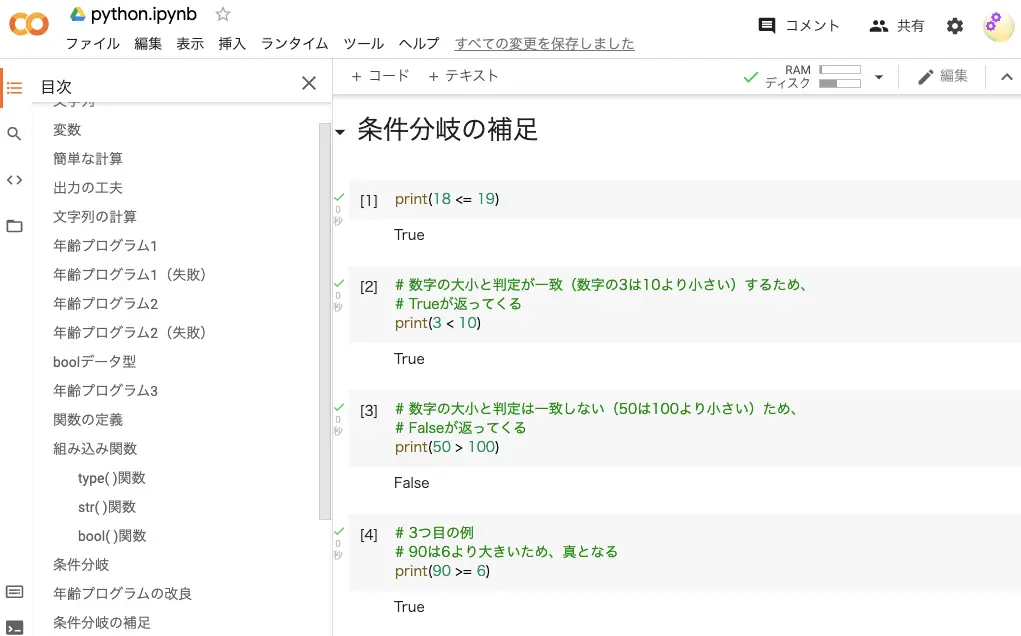
print(18 <= 19)出力: True真偽値、比較演算子については前回の記事で説明しています!
上記コードでは、まず比較演算子「<=」を使って、
18という整数が19より小さいかどうか比較しています。
この式の場合、数字の大小関係は明らか(18 は 19 より小さいという事実)なので、
比較演算子を使った判定は真、つまり True が返されます。
このように比較演算子は式を判定できる機能を持つので、
条件分岐で使用するときは、
判定式が True or False のどちらになるのか常に意識しておく必要があります。
ここで、ほかの比較演算子も紹介します。
| 比較演算子 | 意味 | 例 | 真偽値 |
| a < b | a は b より小さい | 3 < 10 | True |
| a > b | a は b より大きい | 50 > 100 | False |
| a >= b | a は b 以上 | 90 >= 6 | True |
| a == b | a は b と同じ | 10 == 10 | True |
| a != b | a は b と異なる | 70 != 25 | True |
比較演算子の紹介
ここで覚えるというより、「そういうのがあったな」という程度でオーケーです!
上の例を通して、比較演算子に慣れましょう。
数学の復習も兼ねて、最初の例を見ていきます。
この比較演算子( < )は、尖っている方が小さいかどうか(小 < 大)を判定します。
これが成立するなら、判定は True(真)、
しなければ False(偽)が返ってきます。
# 数字の大小と判定が一致(数字の3は10より小さい)するため、
# Trueが返ってくる
print(3 < 10)出力: True# 数字の大小と判定は一致しない(50は100より小さい)ため、
# Falseが返ってくる
print(50 > 100)出力: False
2つ目の例では、50 > 100 という式の大小関係を判定しています。
尖っている方に100 が書かれているので、100 の方が小さいかどうか評価しています。
言い換えると、「50 は 100 より大きいかどうか」を判定していることになります。
そして、数字の大小関係から、これは False が返ってきます。
# 3つ目の例
# 90は6より大きいため、真となる
print(90 >= 6)出力: True
最後の2つは、大小関係というより、
値が同じかどうか判定するときに使います。
# 数字10と数字10は同じなので、Trueが返ってくる
print(10 == 10)
# 数字70と数字25は異なる数字なので、Trueが返ってくる
print(70 != 25)出力: True
数学のイコール(=)と違って、
プログラミングでは値が同じかどうかを評価する際に
イコールを2つ(==)続けて書きます。
また値が異なるかどうかを判定したいときには、
エクスクラメーションマークとイコール(!=)を続けて書きます。
比較演算子はこの程度で十分でしょう。
大事なことは、判定した結果が True もしくは False (bool型)で返ってくることです。
そして条件分岐では、
実はこの結果(True or False)を使った判定を行っていました。
前回は以下のようなプログラムを書きました。
# ageはユーザーからの入力(年齢)でした
age = 20
if age <= 19:
print("お酒は20歳から。")
else:
print("お酒には気をつけましょう。")出力: お酒には気をつけましょう。
たとえば、この条件分岐では変数 age が 19 以下ならば、
「お酒は20歳から。」と出力し、
そうでなければ「お酒には気をつけましょう。」と出力します。
その際の条件式(age <= 19)に比較演算子を使っています。
この場合、age には 20 という値が入っていますので、
以下のように数字を比較する判定が行われます。
20 <= 19この条件式の判定には False が返ってきます。
そのため、else 以下が実行され、
「お酒には気をつけましょう。」と出力されるのでした。
このように条件分岐ではboolデータ型(比較演算子で評価した結果)を使いますので、
覚えておくようにしましょう。
ここまでが条件分岐の補足になります。
次はループとセットで使われることが多いリストを見ていきましょう。
リストは順番をもつケースのようなもの

さっそく、リストについて説明していきます。
これは以前話した変数と似ていて、変数は名前付きの箱で値を一つ保管できました。
リストは同時に複数の値を保管できると覚えてください。
上記の写真を使ってリストをイメージしましょう。
ケース(リスト)には仕切りがあり、それぞれにルアー(要素)が入っています。
※ 要素とは、リスト内にある一つひとつのデータのことを指します
またケース(リスト)の仕切られた区間にはそれぞれ順に番号が振られており、
これをインデックス(要素の位置)とよびます。
注意してほしいことは、このインデックスは「0 スタート」だという点です。
たとえば私たちがケースからルアーを取るとき(左側を先頭とすると)、
「1 個目のルアー」と数えると思います。
しかし、プログラミングのリストにおいては基本 0 スタートなので、
「0 個目のデータ」と数えるのです。
上記の例で言えば、「0 個目のルアー」と表現するということです。
ルール6: インデックスは0スタートです!
ここからは覚え方で、このように 0 から数えるのは、
インデックスは基準(先頭の位置)からの距離で測るからです。
ケース(リスト)の先頭を基準とすると、
一番最初のルアー(要素)は基準と同じ位置にあるため、
基準からの距離は 0 になり、インデックスは 0 になります。
同様にその右隣りは基準から 1 コ隣の場所にあるので、
距離が 1 となり、インデックスは 1 になります。
リストが持つイメージはこんなところです。
実際にプログラムに書いてみましょう。
まずはリストの構文(リストの定義のしかた)です。
# 右辺の角カッコがリスト
# これをtest_listという変数に代入
test_list = []
print("定義されたリスト: ", test_list)
まずは角カッコを書き、それを変数に代入するとリストを定義できます。
上記プログラムではそのリストを出力していますが、
中身は空(カラ)になっています。
この時点では、リストを用意しただけの状態なので、空として表現されるのです。
続いて、この空のリストに値を追加してみましょう。
# 値の追加には.appendを使う
test_list.append('おはよう')
print("値を1つ追加したリスト: ", test_list)値を1つ追加したリスト: ['おはよう']
値を追加するには先のリストの最後尾に「.append( )」を使います。
ドット(.)を忘れないようにしましょう。
※ 「何でドットを使ってそんなことができるのか」については
この先の記事:オブジェクト指向で説明します。
ちなみに、これは関数と似ていますが厳密にはメソッドと呼ばれます。
値を追加したいときは「.append( )」を使えばいいのか、という認識でオーケーです!
リストにもう少し値を追加します。
# 値を2つ追加する(順番に注目)
test_list.append('こんにちは')
test_list.append('こんばんは')
print("あいさつリスト: ", test_list)あいさつリスト: ['おはよう', 'こんにちは', 'こんばんは']
リストを出力すると、
「おはよう」、「こんにちは」、「こんばんは」とリストに追加した値が、
順番に出力されていることに気がつくかと思います。
この順番にというのがリストの特徴で、
データ(値)の数が増えても(減っても)、
きちんと整理された状態で保管されるということです。
【データへのアクセス方法】
ここで、先ほど説明したインデックスを思い出してください。
これはリストに保管してあるデータにアクセスするときに使います。
たとえば、2 番目(先頭から 2 個目)のデータにアクセスしたいときは、
以下のように書きます。
# リスト[インデックス]でアクセスする
print("2番目のデータ: ", test_list[1])2番目のデータ: こんにちは
まずはアクセスの仕方ですが、角カッコで行います。
そして、そのカッコの中にインデックスを書くと、
データが取り出されます。
2 個目のデータは基準(これが 0 個目のデータ)の 1 コ隣なので、
基準からの距離は 1 になります。
そのため、インデックスは 1 と決まるのです。
2 番目のデータだから test_list[2] かな?は、間違いです!
【例外を発生させるインデックス】
リスト内のデータにアクセスするとき、
そのインデックスが存在するかどうか注意してください。
上記で定義したリストには今、3つの要素しか存在しません。
これは組み込み関数の len( ) で確認できます。
# len()関数で、リストの長さ(length)を取得できる
print("リストの長さ(要素の数): ", len(test_list))リストの長さ(要素の数): 3組み込み関数については前回の記事で説明しています!
このコードで確認できるとおり、
現在長さが3(3つの要素を持つという意味)のリストに対して、
リスト内に存在しない4番目の要素にアクセスしようとすると、
例外が発生します。
# たとえば4番目の要素にアクセスしようとした場合
print(test_list[3])IndexError: list index out of rangeこのようにリストの範囲を超えたインデックスを指定すると
例外になりますので、注意しましょう。
【さまざまなデータ型も追加できる】
また、これまでは文字列データ型のみを追加してきましたが、
int や float、boolデータ型などもリストに追加できます。
# 追加できるデータ型は文字列だけではない
test_list.append(100)
test_list.append(3.14)
test_list.append(True)
print(test_list)出力: ['おはよう', 'こんにちは', 'こんばんは', 100, 3.14, True]
最後に次節で使うリストの定義について補足です。
先ほど定義したリストは空の状態でした。
しかし、リストに入るデータがあらかじめ分かっている場合には、
空の状態で定義する必要はありません。
以下のようにデータを用意した状態でリストを定義してもよいのです。
# リストを定義する時点で値を入れることも可能
test_list = ['月曜のタスク', '火曜のタスク', '水曜のタスク']
print("はじめから値が用意されたリスト: ", test_list)
このようにリストを使うことで、
(順番を持つ)複数のデータを 1 つの変数に格納できます。
今はまだこの利点がよくわからないかもしれませんが、
順番を持つデータといえば、たとえば動画データがあげられます。
動画は 1 秒間に(多くの場合)30 枚の写真(フレーム)を連続して表示します。
リストはそういった順番を持つデータを処理する場面で役に立つのですが、
動画(画像)処理の話は次回に譲ります。
そこでリストの扱い方も分かってくるかと思います。
ひとまずこれで繰り返し処理の準備が整いました。
さっそく見ていきましょう。
何度も頼りになる繰り返し処理

ここから面倒な作業を肩代わりしてくれる繰り返し処理の説明です。
ところで、「繰り返して何の意味があるのか?」と思われるかもしれません。
しかし、「繰り返し」というのは実は人間が最も苦手とする作業の一つであり、
それを何度も正確に行えるというのは強力なことなのです。
この先学んでいく、
AIの学習もこの繰り返し処理の中で行われるもので、
何度もなんども同じ作業(処理)を繰り返していくから、
少しづつ賢くなっていけるのです。
そんな繰り返し処理は、ループともよばれ
以下の構文で実現できます。(インデントを忘れないように)
for 変数 in リスト:
処理
今回は、先ほど登場したリストを使ったループの説明をします。
まずは「for 変数」を見てみましょう。
この変数にはリストの要素が順番に入っていきます。
たとえば以下のようなコードがあるとします。
# リストの定義
test_list = ['おはよう', 'こんにちは', 'こんばんは']
for text in test_list:
print(text)出力:
おはよう
こんにちは
こんばんは
まずはこのコードを実行してみましょう。
リストの中身が順に出力されたかと思います。
最初にリストを定義しており、次にループの構文を書いています。
このループの構文がきちんと書かれている場合、
まずリストの最初の要素(今回は ‘おはよう’ )が変数 text に代入されます。
次にインデントされた処理(今回は print(text) )が実行されます。
したがって、今変数 text に格納されているデータ( ‘おはよう’ )が出力されます。
1度の処理はこれで以上となり、繰り返しの1回目が終了します。
しかし、現在リストの長さは3なので、
この繰り返し(処理)が3回行われるまでループは終了しません。
ループはリストの長さ(要素の数)だけ繰り返されます!
そのため、1回目の処理が実行されたあとは、
変数 text にリストの次の要素である ‘こんにちは’ が代入され、
同じようにインデント以下の処理が実行される仕組みになっています。
つまり、リストの要素が存在する限り、
処理を繰り返すのがこの for 文の役割なのです。
※ for :〜する間はずっと(処理するという意味)
最後(3回目)の処理も同様に、
文字列データの ‘こんばんは’ が変数 text に代入され、
print( )関数でその文字列が出力されます。
そして、リスト内のすべての要素に対する処理が済んだため、
ループはここで自動的に終了します。
これがループの概要になります。
さらに詳しいことはその都度説明していきます。
覚えておいてほしいことは、
今回のループがプログラムのもう一方の片輪であることです。
前回登場した片輪の条件分岐と組み合わせることで、
両輪がそろい、ほぼどんな処理も実現できるようになるでしょう。
まとめ
ここでは繰り返し処理やリストについて学びました。
また説明の中でインデックスというワードも登場しましたね。
今後も当然のように使っていきますので、
ここで覚えておくようにしましょう。
さらに新しい組み込み関数も登場しました。
len( )関数はよく使われますので、これもおさえておくとよいでしょう。
今回出てきたルールは以下の通りです。
ルール6: インデックスは0スタートまた、条件分岐の補足で比較演算子が行う判定も見てきました。
今回のプログラムに条件分岐は登場しなかったですが、
次回、ループと組み合わせようと思います。
次回は繰り返し処理2(while文)について説明し、動画を処理します。
【P.S.】
@AI_JUVETをフォローしていただけると大変励みになります🙂


コメント